UVM dissection – statistics
UVM code reuse is predominantly a framework reuse model. It’s effective application requires certain level of source code exposure as discussed in the “UVM dissection –…
UVM code reuse is predominantly a framework reuse model. It’s effective application requires certain level of source code exposure as discussed in the “UVM dissection – Why it’s needed?“
First level of dissection is some vanity statistics. Statistics provides the idea about the scale. When the magic “uvm_pkg” is imported in verification environment, what do I get? Has this question ever crossed your mind? One can say why do I care? It’s tradition, we just include and move on with the business of verification.
The reason we need to care is there is price to be paid. UVM source code may be free. But simulator licenses are not free. Compute farms where the simulations are being run are not free. I can enumerate many others that are not free but let’s just stop here. Point is UVM also needs to be compiled and simulated too. That costs simulator licenses and computer farms.
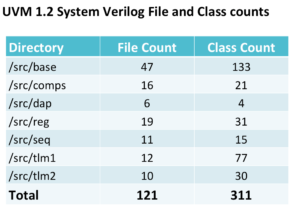
UVM uses the DPI written in C/C++. I am not including the DPI details here at the moment. Lets focus from the System Verilog part of it. When you include the magic uvm_pkg, as of UVM 1.2 implementation you are getting 121 files and 311 classes. Your verification environment may have 10 files and 20 classes but just by including the uvm_pkg your class count would be shot up by 311. Note that UVM needs compilation. See your compile log file. When the simulation is started these classes will have to be loaded. Look at the class hierarchy shown in the interactive debuggers.
Don’t worry about it. With the growth in the compute power, Focus has been on the human effort minimization and not the computer resource optimization as a first priority. But the point is, since you are paying price by including uvm_pkg make it count by extracting the best productivity boost out of it.
Next level of dissection is all UVM dissection – class hierarchy.