Effective randomization in Constrained Random Verification
One of the key component of coverage driven constraint random verification environment is randomization. High-level verification languages provide various constructs to implement the randomization. However…
One of the key component of coverage driven constraint random verification environment is randomization. High-level verification languages provide various constructs to implement the randomization. However that is not the focus of this article.
In spite of rich randomization constructs, many of the constrained random verification environments fail to achieve the optimum results either due to excessive or insufficient randomization. This article will focus on addressing how to hit that balance.
How to effectively use the randomization to meet the verification goals? Let’s find out the answers by asking more questions and answering them below. We can call these as requirements for the randomization. Next in the series we will consider how to meet these requirements one of the popular HVLs.
Why do we use randomization?
Consider a design state space and feature combinations that are so large, that it’s practically impossible to enumerate and cover all of them exhaustively. This is a scenario, suitable to be addressed by randomization. Randomization of the stimulus will explore the state space and combinations, which we cannot manually enumerate.
Among this large state space and feature combinations, the critical ones are covered through functional coverage. This is to ensure that critical functionality is not left to chance for coverage. What about the state space not captured by the functional coverage? It’s a risk. Functional verification is not a process to guarantee that there are no more bugs at all in the design. That is near impossible and would need infinite resources. It’s a process to reduce the risk. Reduce the risk by investing limited resources where it matters most.
For a give feature if entire design state space can be enumerated and each of combinations is equally important then do not wait for constrained random to cover it. For example no need to verify 2 input nand gate and 4-bit counter with the constrained random verification. It’s trivialized here but even in complex design there are certain areas, which are important and enumeratable, go ahead and sweep them all with programmable test.
What to randomize?
Every variable should be randomized. Purists go to an extent of even randomizing a constant. That is by declaring constant as variable and then constraining the variable to a specific value. It may seem like extreme but it makes a point that if the constant turns out to be variable later the constraint is put in place.
Does everything randomized should be controllable?
Yes, of-course. Problems due to uncontrolled randomizations far outweigh any benefits it may provide. Anything randomized should be controllable. Test or higher layer may control it to achieve verification goals.
Verification goals can be met effectively only if the verification environment is controllable and observable. The goals of verification cannot be confirmed to have met with the uncontrolled randomization. Simulation based verification has key responsibility to provide the results in a linear converging form to enable closures. Bug hunting approaches of verification such as mutation testing and formal verification do not have that constraint.
Does controllable randomization mean test or higher layer will control each and every randomization in test bench?
No. It may not. But when a test or higher layer wants to control the randomization it should be able to control it.
By default all randomizations should randomize to valid range possible for respective variables. But when test wants to control there should be a clean and graceful way provided.
Let’s take a simple example of bus functional model(bfm) that is expected asserts the acknowledgement signal in 1 to 5 clock cycles after the request is asserted. The block of bfm asserting acknowledgement should randomize the delay between 1 to 5 clock cycles by default. But it should not be hardcoded internally. These delay values should be captured as minimum and maximum acknowledgement delay variables in the bfm configuration and constrained to 1 and 5 respectively. By default it will randomize to valid range controlled by these variables. But if the test wants to control it, it can do so by changing it in the configuration object. This is a very basic example for making randomization controllable and how it gets used.
What are the different types of randomizations done in a verification component?
Verification component have two types of randomizations.
- External randomization
- Internal randomization
An external randomization allows ability for the other components to control the behavior of the verification component. They are typically of the following type:
- Configuration randomization
- Transaction randomization
Internal randomization is used for providing variation of the functionality of the component. It’s controlled by configuration and transactions. This enables indirect control by the test or higher layer.
How to encapsulate randomizations?
Randomizations are primarily encapsulated in two types of objects in testbench. They are configuration and transaction. Both can be hierarchical depending on the complexity of test bench. There are multiple of them used in test bench. A typical usage is described below.
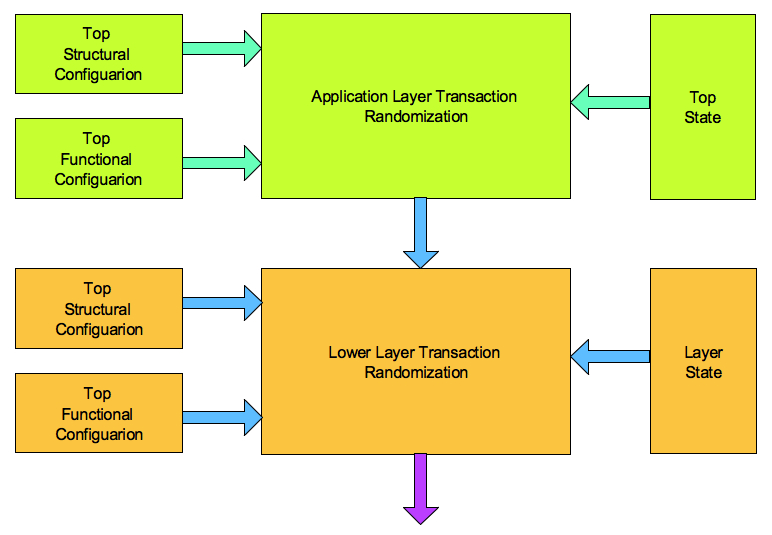
A test bench can have top-level structural and functional configurations. Structural configuration decides the structure of the test bench. While functional configurations contains programmable variables of the test bench components. DUT configurations are encapsulated separately. All these configurations are randomized between the legal ranges. Programmable variables can be derived from the specification or features of implementation.
The highest layer of test bench is application level stimulus generation. Application level stimulus generation is encapsulated as transaction. Application level stimulus can be both data and control stimulus. It’s always advisable to encapsulate the data and control stimulus separately.
Stimulus generation randomization takes in to consideration the structural configuration, functional configuration and current state of the design to set the range for the randomization.
Test bench layers translate and program the application level stimulus to low level stimulus to design for execution. Lower layer stimulus is also encapsulated as transaction. Randomization of low-level transaction is based on high-level transaction and the layer’s configuration & state.
Normal operation stimulus generation is controlled through configuration randomization and transaction randomization. Transaction randomization is constrained by the respective configuration and state.
There is one more configuration called error configuration. Error injection randomization is encapsulated in the error configuration. Randomized error configuration is applied for the transaction to corrupt it. Type of the error to be injected and corrupted value to be used are captured in the error configuration.
An error configuration randomization is controlled by structural configuration, functional configuration, state and transaction being corrupted. Based on the transaction sub-set of applicable corruptions are considered for the application and selected randomly. The layer responsible for the corruption will process the error configuration and corrupt the transaction appropriately. Every layer, which implements the corruption, should encapsulate its own error configuration.
What should be the order and frequency of randomization?
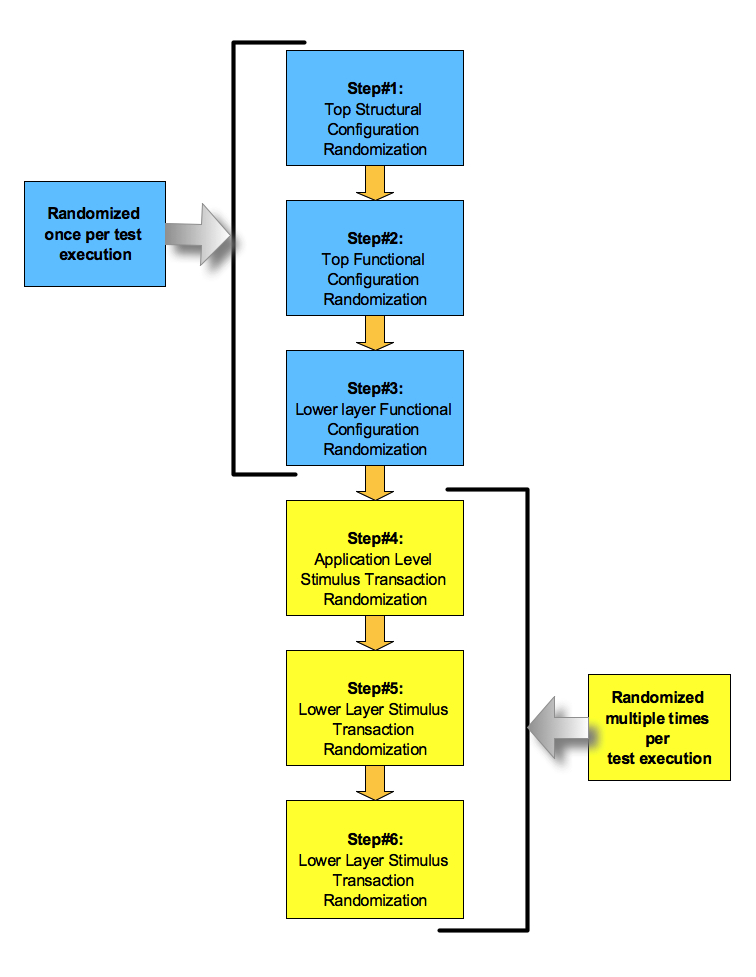
Logically first randomization is structural configuration randomization. Structural configuration randomization information is used for constructing the verification environment. After the verification environment is constructed the top functional configuration is randomized.
Top-level functional configuration serves as a reference for various lower level verification components functional configuration is randomized.
Typically structural and functional configuration hierarchy is randomized only once for every test. It typically remains same for the entire execution of the test.
Next step is the application level stimulus transaction randomization. Application level stimulus transaction is randomized several numbers of times to meet the intent of the test.
Application level stimulus transaction is transformed to lower layer transactions for stimulating design. If error injection is enabled, the error configuration randomization will take place for the corrupting selected lower level transactions.
The lower level transaction corruption is typically controlled by the percentage of corruption. Time slot driven approach where for random duration of turning error injection on and off can also be used. Error configuration randomization is also done several numbers of times during the execution of the test.