Error injection is a complex area in all its related dimensions. Supporting it in bus functional models(BFM) is also not an exception. Care has to exercised, if not it can easily create mess. Danger is it will affect the stability of the bus functional model in all areas.
Keep in mind, BFM’s default mode of operation will be normal operation. Verification will use normal operation mode for 70 % of time and 30 % time it will use it for error injection.
Error injection support implementation in BFMs, is like swimming against the current of river. Bus functional model architecture has these contradictory requirements to be fulfilled. On one hand, they have to model the normal operation and an on other error injection. Both have to be housed together in the same enclosure. Error injection is like living being with contagious disease and normal operation is like healthy living beings. Now if the error injection is not quarantined it will spread the disease to other parts of the BFM. Thus affecting the overall code stability of the BFM.
We certainly don’t want the code that is used for the 70 % of the time to be affected by the code that’s used for the 30 %.
In next few sections let’s look at some of the ways to cleanly structure the error injection implementation in BFM.
We have already seen the requirements for the error injection support from BFM in the “Error injection capabilities of bus functional models”.
Error injection support is made up of three major functional areas:
- Randomization of the error configuration
- Applying the error configuration to the protocol data unit
- Checking the response from the DUT on the line
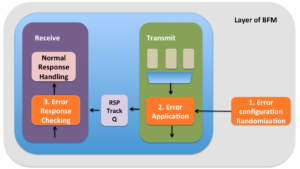
1. Error configuration randomization
Error configuration contains information about the type of corruption and selection among the variations for the corruptions. Field corruption variations consist of different illegal values for a selected field. Sequence corruption variations consist of different possible protocol data units. Typically a error configuration per protocol data unit is desired.
First level of quarantining is avoiding merging of error configuration and the respective protocol data unit class. Eve when it may seems tempting to do so.
Every layer should have it’s own error configuration. It should not be mixed with the other layer. Some layer can have multiple error configurations, if it supports multiple distinct functionalities. A typical link layer for example would support three major functional areas, link initialization, link layer control and supporting data flow of upper layer. These are clearly three different areas and it’s okay to have three different error configurations to control the error injection in respective areas.
Properties representing type of corruption and selection among variations of corruptions, in the error configuration class will have to be random and constrained to correct values. In order for the constraints to be implemented correctly the respective layer configuration and state information is also required. The layer configuration is required to tune the the randomization as per the DUT configuration. The definition of the legal range is typically dependent on the configuration of the system. The definition of the legal sequence is typically dependent on the state. So the correct the corrupted value generation will be dependent on both of these. Error configuration should have access to the corresponding protocol layer’s configuration and state objects as well.
Apart from that sometimes layers may operate very closely. In such case the error injection in one the layer can have effects on another layer. This may appear like breaking the abstraction of layering but note that it’s protocol design. So in such cases the error injection information about related layers will have to be exchanged with each other.
The protocol data unit corrupted should hold the error configuration with which its corrupted. This will ease the debug process.
Error configuration should also have ability to generate the different errors based on the weights specified for different error types.
Error configuration randomization should be able to generate the one of the valid error types and select the one of the correct illegal variations for the injection, given the corresponding protocol data unit, layer’s configuration, layer’s state and optionally the weights for the different error types. Setting up these constraints is not a simple task. It takes few iterations to settle down. Key to getting right quickly is, in case of failures do not do point thinking, go after the root cause. In case of error injection all problems need due attention. Either at the point of problem or later they will claim their share of time and effort. So better give it early and close it right.
2. Error configuration application
Applying error configuration means executing the information present in it. If its field corruption, the corresponding field in the protocol data unit will be overwritten with its corresponding corrupted value generated in the error configuration. If it’s the sequence corruption the current protocol data unit will be replaced with the corrupted protocol data unit. At times this could be null. Which is meant for creating the missing protocol data units scenarios.
Now applying the error configuration may sound simple. Yes it is simple. Challenge is in selecting the right point for applying it in data flow path. It may sound very tempting to distribute it at various points in your data flow paths. This is strict no. Do not puncture the normal operation data flow path at multiple places. Minimize the point of corruptions. Best is single point of corruption. Pick a point in data flow where all the protocol data units of layer pass through and corrupt it at only this point. This helps to keep this part of the error injection logic quarantined to a specific point.
At times it may not be possible to restrict it to single point. Especially when the layer has multiple distinct major functionalities. Link layer for example. It will contain the initialization, layer control sequences and data flow from upper layer. All these three are distinct functionalities and may need a different point of error configuration application. In such cases one point per each functional area is appropriate. Bottom line is keep these points to as minimum and clean as possible.
3. Error response checking
The response from the DUT for the error injection needs to be checked at two interface:
- Recovery: For some errors are recovered in hardware driven recovery protocol. This is accomplished by initiating protocol defined recovery sequence on the line. This will be visible to BFM.
- Reporting: The error detected will have to be reported to application. Sometimes internal statistics counters maintained in the hardware will have to be updated. This typically accomplished with the interrupts and status registers. This will not be directly visible to BFM. This has to be checked by tests or test bench.
Recovery mechanism action will be visible to the BFM. So BFM will have to set up expectations to check if this recovery sequence has been triggered. For the error injection done from the transmit side of the BFM, the expectations for checking the recovery sequence will have to be passed to receive side. Its best to setup a tracker queues through which the transmitter can pass the information about the expectations on the response with the receive side. As indicated the corrupted protocol data units must contain the error configuration associated with it. This protocol data unit will have to be passed to receiver for checking error response.
On receive side whenever it finds the tracker entries that have the protocol data units with valid error configurations, checking should be implemented as separately as possible from normal operation checking. Checking logic is one of the parts of the logic where clean quarantining can be challenging. This is because of the reuse of checking logic between the normal operation and error response checking.
The expected response also being set up as a part of the error configuration itself is a good idea. This provides the flexibility for tests to tune the checking as per slight variations in the DUT implementation, when required.
Key to successful implementation of the error injection support is to keep it quarantined as much as possible from the normal operation data path. Allow as much flexibility in this logic as possible in both stimulus generation and especially in response checking to accommodate the unforeseen scenarios.
Which can be many !
Leave a Reply
You must be logged in to post a comment.